EDA for EDA
Event-Driven Ansible for Event-Driven Architecture
Event-Driven Architectures are a popular choice for modern application development. The release of Event-Driven Ansible allows the Ansible Automation Platform to take automated actions in response to events from across the IT environment. While Event-Driven Ansible can be hooked up directly to specific event sources, we want to show that it can provide even more value by becoming a key component of an overall Event-Driven Architecture.
What are some of the best ways we can make use of EDA for EDA? And what are some ways to use Event-Driven Architecture principles to help with Event-Driven Ansible?
Note: For the rest of this post, I’m going to use EDA as the acronym for Event-Driven Ansible and spell out Event-Driven Architecture in full.
Why use an Event-Driven Architecture?
The benefits of Event-Driven Architecture are well-known. This article outlines some of them. In the specific areas where Event-Driven Ansible is deployed, these benefits include the following:
Multiple Producers
Using an Event-Driven Architecture lets us integrate events from any number of event “producers”, and handle them as though they all originate from a single producer. This would normally require the producers to agree on a format for the event data, but this can also be mandated through the use of API Schema contracts for events. In the EDA context, EDA can then treat a series of events as though they were coming from one source, and use rulebooks to process them accordingly. For example, events from a hardware monitoring tool and software monitoring agents may all send events to a single event queue for processing by EDA.
Multiple Consumers
A single event in an Event-Driven Architecture may be consumed and processed by multiple “consumers”. One of those consumers may be EDA, but potentially the same events might also be handled by other consumers - a Security Information and Event Management (SIEM) system for example. An Event-Driven Architecture means that your event producers don’t have to be modified to cope with more consumers as they are added.
Data Transformation
Most Event Broker systems will allow for transformation of event data within the broker. This could be used to ensure events from multiple event producers meet a common format, or may allow for the augmentation of events with additional data. Similarly, it can also be used to strip the event data down to only include the information relevant for further processing.
Data Filtering
Events may also be filtered as part of the Event-Driven Architecture. For EDA, where it is likely that we only need to handle a certain volume of events, we can use the Event Broker to filter the list of events that are sent to EDA directly. EDA rulebook processing may then further filter events to only handle the ones that require automation.
Decoupled Applications
The big advantage of an Event-Driven Architecture is to decouple the producers and consumers of events:
“An event producer doesn’t have to know who is going to consume the event, and an event consumer doesn’t have to know who is going to produce the events it consumes.”
This gives a lot of flexibility in being able to replace or augment components of the architecture independent of one another. If you were to hook an event source (eg. Dynatrace) up directly to EDA, but later on you decide to replace Dynatrace with another source of events, you need to change both the Dynatrace / monitoring side, but also your EDA configuration. If, instead, you are using an Event broker, you can swap out the Event producer for another system, as long as the event format sent to the Event Broker is the same. Similarly, if for some reason you decide you want to use some other system to handle events in your environment, you can swap out EDA for another system (but why would you?) without making any change to the producers of events. It also means these migrations don’t have to be a hard failover, you can add in producers or consumers, then failover or rollback without any change to the systems being replaced.
This decoupling also means the various components in your Event-Driven Architecture may be running on different platforms and different technology stacks. You may have event producers running as virtual machines or as containers, either on-premises or in the cloud, but the other parts of your architecture don’t have to know anything about those tech stacks.
EDA and Kafka
Apache Kafka is one of the leading Event-Driven Architecture solutions. There are many implementations of the upstream open source Kafka project, including one from Red Hat - “streams for Apache Kafka”.

Kafka provides an event broker mechanism with high resilience and scalability in mind. It uses the concept of ‘topics’ which are basically queues of events. Producers post events to topics, and consumers subscribe to topics to receive new events. Kafka Brokers use partitions to ensure high availability and resilience. The Kafka ecosystem also includes a set of additional tools that support integration with external data systems, allow for transformation of data, and provide data mirroring and disaster recovery functions.
For the purposes of EDA, Kafka is a great way to introduce an event broker mechanism between event producers and EDA rulebook activations. The diagram below shows an example of this architecture.
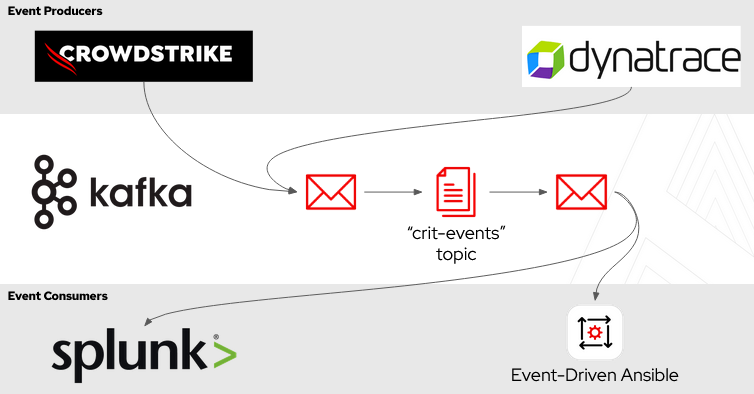
In this case, events are being produced by both Crowdstrike and Dynatrace. These events are all being placed into a single Kafka cluster, including a topic called “crit-events” for critical incidents or outages. EDA and Splunk are both consumers of the “crit-events” topic. EDA can respond to certain events on the “crit-events” topic and launch automation jobs. Splunk can consume and process the same events independently of EDA. In fact, the same system could be both a producer and a consumer of events. So Splunk could be consuming environmental events, but if its analysis detects something of note, it could produce a higher level or more directed event for other systems to handle.
Deploying Kafka
Red Hat’s build of Apache Kafka, “streams for Apache Kafka” can either be deployed onto RHEL directly, or deployed in an OpenShift environment using the AMQStreams Operator (based on the Strimzi upstream project). The operator makes it really easy to quickly deploy a scalable, highly available Kafka cluster to get started with your Event-Driven Architecture.
Both the cluster itself, and the topics available on the cluster, can all be specified as Kubernetes custom resources (CRs) which means you can deploy them using config-as-code and GitOps pipelines.
For a VM-based deployment on RHEL, there is an Ansible Collection available for AMQStreams to help automate your Kafka deployments.
Connecting EDA to Kafka
EDA can be configured with an event “source” of a Kafka cluster. For Red Hat’s “streams for Apache Kafka” we specify the source as the Kafka “bootstrap” server hostname. The mechanisms used to secure access to Kafka can vary, and we need to very carefully specify the right parameters in the source definitions to ensure that EDA can connect to Kafka correctly.
In my experience, this can be very difficult to diagnose. Often EDA will log out every appearance of having connected to the Kafka topic, but if the connection parameters are incorrect, you may just fail to observe any events actually being received by EDA. For demo purposes, I normally tell EDA not to verify the hostname against certificates, and to use the CERT_OPTIONAL validation mode, while connecting to the Kafka PLAINTEXT endpoint. Use of a properly authenticated and encrypted endpoint requires much more configuration.
A sample rulebook excerpt showing the kafka source is included below.
sources:
- name: Listen to Kafka server broker
ansible.eda.kafka:
topic: "{{ kafkatopic }}"
host: "{{ kafkahostname }}"
port: "{{ kafkaport }}"
group_id: "{{ kafkagroupid }}"
# Note that the following lines are insecure and should
# not be used in a production environment
check_hostname: false
verify_mode: CERT_OPTIONALNote here that the Kafka hostname, port and topic are specified as Ansible vars, which are passed to the rulebook activation as parameters inside EDA.
The group_id parameter indicates the consumer group identifier. This isn’t strictly necessary for connecting to Kafka if you aren’t grouping consumers.
Rulebooks in EDA
Once your source is correctly set up, you can now define EDA rules to trigger on certain events consumed from your Kafka topic. The sample code below shows a very simple scenario:
rules:
- name: Trigger automation job
# The following condition should be triggered for every
# Kafka event. A proper rulebook would apply filtering
# to the events (on event.body.*) to limit the number
# of triggered actions
condition: event.meta is defined
actions:
- run_job_template:
name: "{{ aapjobtemplatename }}"
organization: midrange
extra_vars:
trigger_type: event_has_metaThe Kafka EDA source always adds a meta component to the event object with metadata about the event. Similarly, the event.body object will contain the Kafka event itself. In a proper rulebook, this would allow you to access details about the event to potentially further filter events, or to trigger different tasks depending on the event contents. In this case, the rulebook simply runs a job template for every event consumed from Kafka. Inside the AAP job that is run, the playbook will have access to the same data from Kafka in the ansible_eda.event.body var.
Important Tip! Ensure that your job template is set to “ask for variables on launch”, otherwise the ansible_eda var will not be available to your playbook.
For a full demo of an Apache Kafka cluster acting as a broker between Advanced Cluster Security (as the event producer) and EDA (as the event consumer), be sure to check out Simon Delord’s demo of closed-loop automation to immediately remediate Kubernetes deployments that breach security compliance policies here. A repo containing the code and with more details about the implementation is here.
Wrapping It Up
Apache Kafka provides an Event-Driven Architecture capability allowing us to decouple the producers of event data from the consumers of that data. While we can connect Event-Driven Ansible directly to an event source (Crowdstrike or Dynatrace, for example), using an Event Broker like Kafka as a connector gives us benefits in terms of performance, resilience and stability. Decoupling our producers and consumers also lets us swap components in and out according to changing requirements, without having to change all of our other components to suit.